Движок Таблицы SharedMergeTree
* Доступно исключительно в ClickHouse Cloud (и облачных сервисах первого уровня)
Семейство движков таблиц SharedMergeTree является облачным аналогом движков ReplicatedMergeTree, оптимизированным для работы на общих хранилищах (например, Amazon S3, Google Cloud Storage, MinIO, Azure Blob Storage). Для каждого конкретного типа движка MergeTree существует аналог SharedMergeTree, т.е. ReplacingSharedMergeTree заменяет ReplacingReplicatedMergeTree.
Семейство движков таблиц SharedMergeTree управляет ClickHouse Cloud. Для конечного пользователя ничего не нужно менять, чтобы начать использовать семейство движков SharedMergeTree вместо основанных на ReplicatedMergeTree. Оно предоставляет следующие дополнительные преимущества:
- Более высокая пропускная способность вставок
- Улучшенная пропускная способность фонового слияния
- Улучшенная пропускная способность мутаций
- Более быстрые операции масштабирования вверх и вниз
- Более легкая сильная согласованность для запросов select
Значительным улучшением, которое предоставляет SharedMergeTree, является более глубокое разделение вычислений и хранения по сравнению с ReplicatedMergeTree. Вы можете увидеть ниже, как ReplicatedMergeTree разделяет вычисления и хранение:
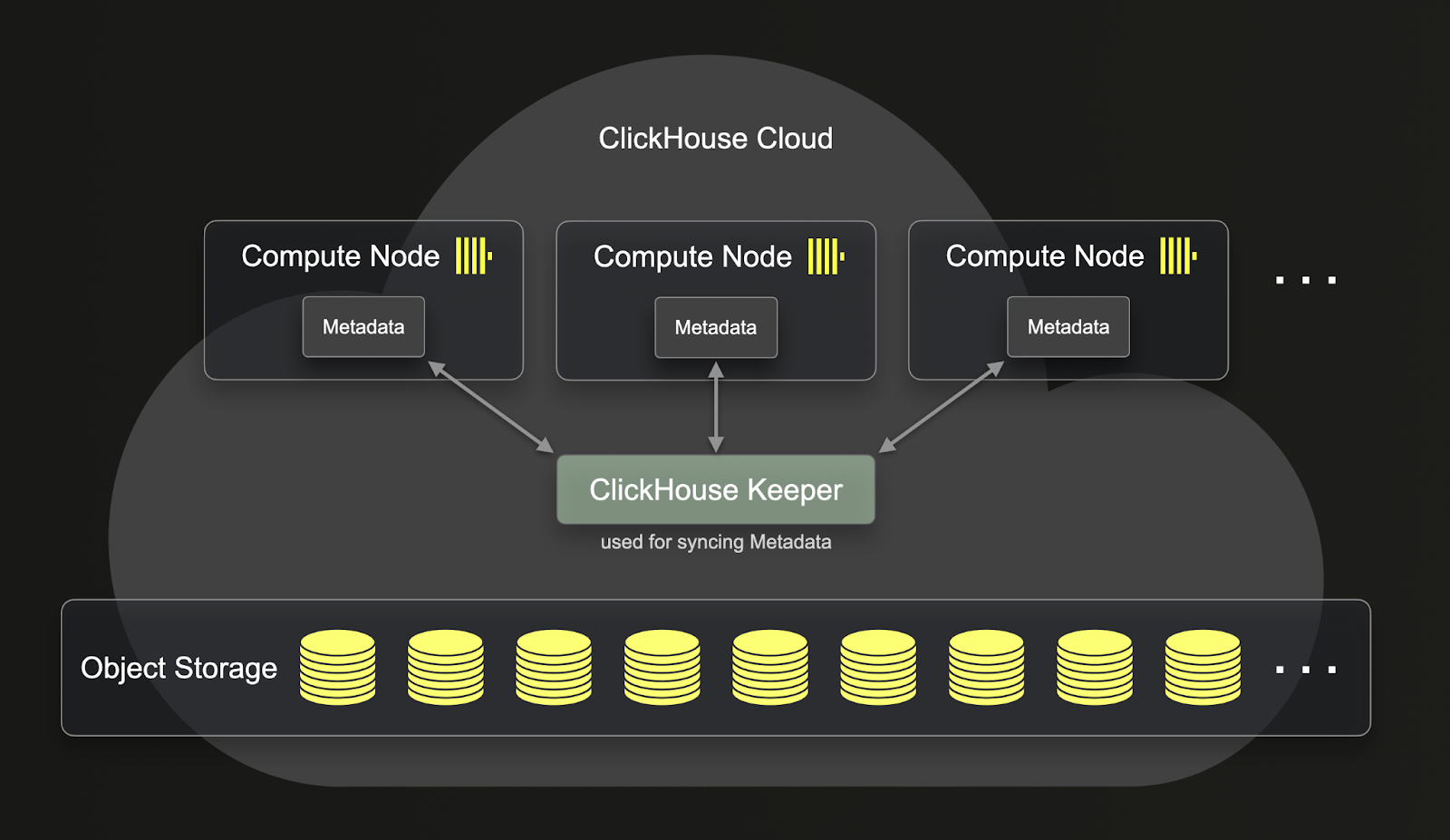
Как вы можете видеть, даже несмотря на то, что данные, хранящиеся в ReplicatedMergeTree, находятся в объектном хранилище, метаданные по-прежнему находятся на каждом из серверов clickhouse. Это означает, что для каждой реплицированной операции также нужно реплицировать метаданные на всех репликах.
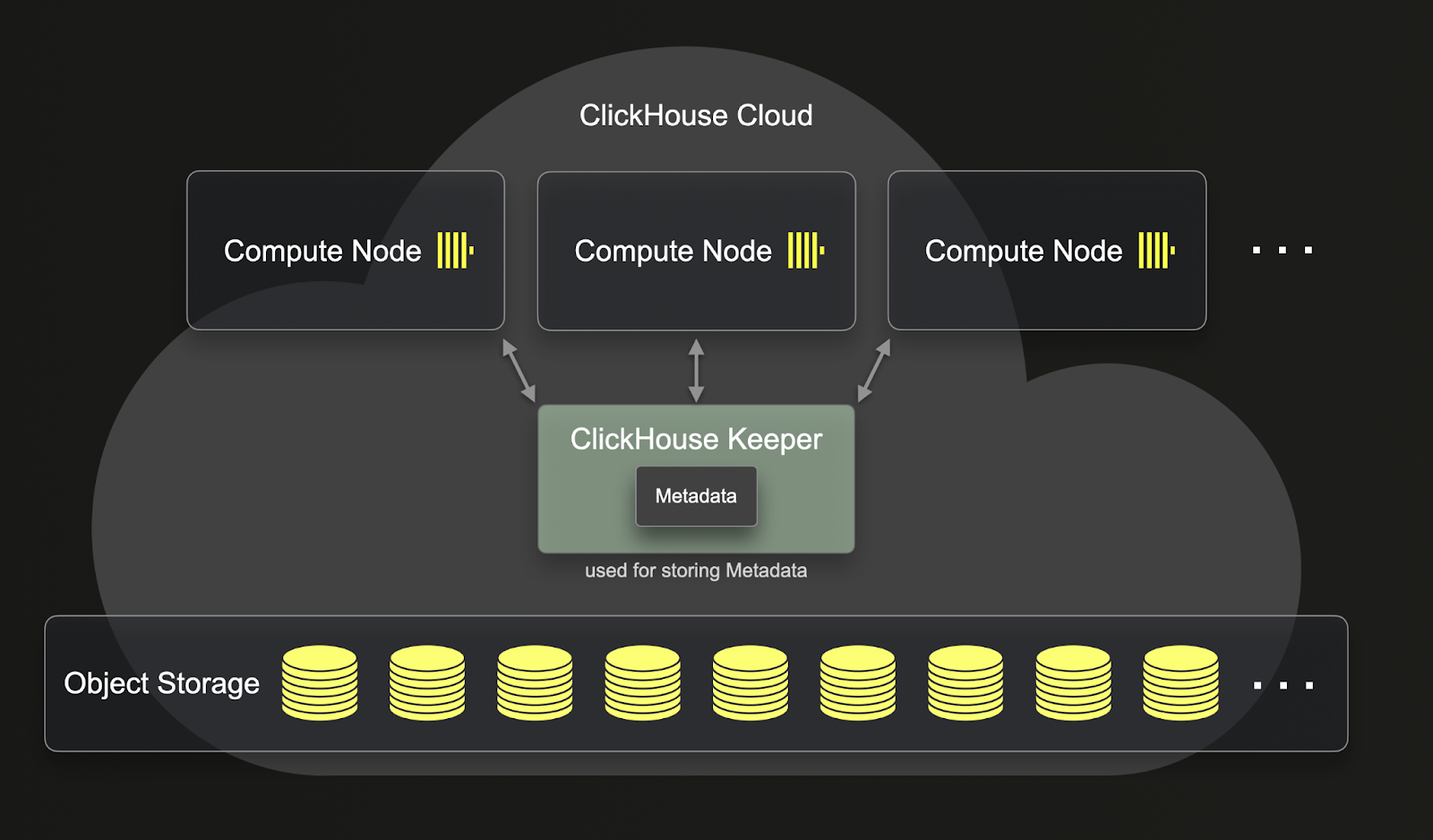
В отличие от ReplicatedMergeTree, SharedMergeTree не требует, чтобы реплики взаимодействовали друг с другом. Вместо этого вся связь происходит через общее хранилище и clickhouse-keeper. SharedMergeTree реализует асинхронную репликацию без лидера и использует clickhouse-keeper для координации и хранения метаданных. Это означает, что метаданные не нужно реплицировать, по мере масштабирования вашего сервиса вверх и вниз. Это приводит к более быстрой репликации, мутациям, слияниям и операциям масштабирования. SharedMergeTree допускает сотни реплик для каждой таблицы, что позволяет динамически масштабироваться без шардов. В ClickHouse Cloud используется подход распределенного выполнения запросов для того, чтобы использовать больше вычислительных ресурсов для запроса.
Интроспекция
Большинство системных таблиц, используемых для интроспекции ReplicatedMergeTree, существуют для SharedMergeTree, за исключением system.replication_queue и system.replicated_fetches, так как репликация данных и метаданных не происходит. Однако для этих двух таблиц у SharedMergeTree есть соответствующие альтернативы.
system.virtual_parts
Эта таблица служит альтернативой system.replication_queue для SharedMergeTree. Она хранит информацию о самом последнем наборе текущих частей, а также о будущих частях в процессе, таких как слияния, мутации и удаленные разделы.
system.shared_merge_tree_fetches
Эта таблица является альтернативой для system.replicated_fetches в SharedMergeTree. Она содержит информацию о текущих выполняемых извлечениях первичных ключей и контрольных сумм в память.
Включение SharedMergeTree
SharedMergeTree включен по умолчанию.
Для сервисов, которые поддерживают движок таблиц SharedMergeTree, вам не нужно ничего включать вручную. Вы можете создать таблицы так же, как это делали ранее, и она автоматически будет использовать движок на основе SharedMergeTree, соответствующий движку, указанному в вашем запросе CREATE TABLE.
Это создаст таблицу my_table, используя движок таблицы SharedMergeTree.
Вам не нужно указывать ENGINE=MergeTree, так как default_table_engine=MergeTree в ClickHouse Cloud. Следующий запрос идентичен предыдущему.
Если вы используете Replacing, Collapsing, Aggregating, Summing, VersionedCollapsing или Graphite MergeTree, это будет автоматически преобразовано в соответствующий движок таблицы на основе SharedMergeTree.
Для данной таблицы вы можете проверить, какой движок таблицы был использован с помощью оператора CREATE TABLE, выполнив SHOW CREATE TABLE:
Настройки
Некоторые настройки в значительной степени изменили свое поведение:
insert_quorum-- все вставки в SharedMergeTree являются кворумными вставками (записываются в общее хранилище), поэтому эта настройка не требуется при использовании движка таблицы SharedMergeTree.insert_quorum_parallel-- все вставки в SharedMergeTree являются кворумными вставками (записываются в общее хранилище), поэтому эта настройка не требуется при использовании движка таблицы SharedMergeTree.select_sequential_consistency-- не требует кворумных вставок, вызовет дополнительную нагрузку на clickhouse-keeper при выполнении запросовSELECT.
Согласованность
SharedMergeTree обеспечивает лучшую легкую согласованность, чем ReplicatedMergeTree. При вставке в SharedMergeTree вам не нужно указывать такие настройки, как insert_quorum или insert_quorum_parallel. Вставки являются кворумными вставками, что означает, что метаданные будут храниться в ClickHouse-Keeper, и метаданные реплицируются как минимум в кворум ClickHouse-keepers. Каждая реплика в вашем кластере будет асинхронно получать новую информацию от ClickHouse-Keeper.
В большинстве случаев вам не следует использовать select_sequential_consistency или SYSTEM SYNC REPLICA LIGHTWEIGHT. Асинхронная репликация должна покрывать большинство сценариев и иметь очень низкую задержку. В редких случаях, когда вам абсолютно необходимо предотвратить устаревшие чтения, следуйте этим рекомендациям в порядке предпочтения:
-
Если вы выполняете свои запросы в одной и той же сессии или на одной и той же ноде для ваших чтений и записей, использование
select_sequential_consistencyне требуется, поскольку ваша реплика уже будет иметь наиболее актуальные метаданные. -
Если вы записываете в одну реплику и читаете из другой, вы можете использовать
SYSTEM SYNC REPLICA LIGHTWEIGHT, чтобы заставить реплику получить метаданные из ClickHouse-Keeper. -
Используйте
select_sequential_consistencyв качестве настройки в рамках вашего запроса.