Заполнение данных
Независимо от того, новый вы пользователь ClickHouse или отвечаете за существующее развертывание, пользователям неизбежно потребуется заполнить таблицы историческими данными. В некоторых случаях это относительно просто, но может усложниться, когда необходимо заполнить материализованные представления. Этот гид документирует некоторые процессы для этой задачи, которые пользователи могут применить к своему кейсу.
Этот гид предполагает, что пользователи уже знакомы с концепцией Инкрементных материализованных представлений и загрузки данных с использованием табличных функций, таких как s3 и gcs. Мы также рекомендуем пользователям прочитать наше руководство по оптимизации производительности вставки из объектного хранилища, советы из которого можно применить к вставкам в этом руководстве.
Пример набора данных
На протяжении этого руководства мы используем набор данных PyPI. Каждая строка в этом наборе данных представляет загрузку пакета Python с использованием инструмента, такого как pip.
Например, подмножество охватывает один день — 2024-12-17 и доступно публично по адресу https://datasets-documentation.s3.eu-west-3.amazonaws.com/pypi/2024-12-17/. Пользователи могут выполнять запросы:
Полный набор данных для этого бакета содержит более 320 ГБ файлов parquet. В примерах ниже мы намеренно нацелимся на подмножества, используя шаблоны glob.
Мы предполагаем, что пользователь получает поток этих данных, например, из Kafka или объектного хранилища, для данных после этой даты. Схема для этих данных показана ниже:
Полный набор данных PyPI, состоящий из более чем 1 триллиона строк, доступен в нашей публичной демо-среде clickpy.clickhouse.com. Для получения дополнительных деталей об этом наборе данных, включая то, как демо использует материализованные представления для повышения производительности и как данные пополняются ежедневно, см. здесь.
Сценарии заполнения
Заполнение данных обычно требуется, когда поток данных принимается с определенного момента времени. Эти данные вставляются в таблицы ClickHouse с инкрементными материализованными представлениями, которые активируются при вставке блоков. Эти представления могут преобразовывать данные перед вставкой или вычислять агрегаты и отправлять результаты в целевые таблицы для дальнейшего использования в прикладных приложениях.
Мы постараемся охватить следующие сценарии:
- Заполнение данных с уже существующим приемом данных — загружаются новые данные, и исторические данные необходимо заполнить. Эти исторические данные были определены.
- Добавление материализованных представлений к существующим таблицам — необходимо добавить новые материализованные представления к настройке, для которой уже были заполнены исторические данные, и данные уже потоковы.
Мы предполагаем, что данные будут заполнены из объектного хранилища. В любом случае мы стремимся избежать пауз в вставке данных.
Рекомендуем заполнять исторические данные из объектного хранилища. Данные следует экспортировать в Parquet, если это возможно, для оптимальной производительности чтения и сжатия (уменьшение сетевой передачи). Предпочтительный размер файла составляет около 150 МБ, но ClickHouse поддерживает более 70 форматов файлов и способен обрабатывать файлы любого размера.
Использование дублирующих таблиц и представлений
Для всех сценариев мы полагаемся на концепцию "дублирующих таблиц и представлений". Эти таблицы и представления представляют собой копии тех, которые используются для живого потокового данных и позволяют выполнять заполнение в изоляции с простым способом восстановления в случае сбоя. Например, у нас есть основная таблица pypi и материализованное представление, которое вычисляет количество загрузок по проекту Python:
Мы заполняем основную таблицу и сопутствующее представление подмножеством данных:
Предположим, мы хотим загрузить другое подмножество {101..200}. Хотя мы могли бы вставить напрямую в pypi, мы можем выполнить это заполнение в изоляции, создав дублирующие таблицы.
Если заполнение потерпит неудачу, это не повлияет на наши основные таблицы, и мы просто можем усечь наши дубликаты и повторить.
Чтобы создать новые копии этих представлений, мы можем использовать CREATE TABLE AS с суффиксом _v2:
Мы заполняем это нашим 2-м подмножеством примерно того же размера и подтверждаем успешную загрузку.
Если мы ощутим сбой в любой момент в течение этой второй загрузки, мы можем просто усечь pypi_v2 и pypi_downloads_v2 и повторить загрузку данных.
С завершением загрузки данных мы можем переместить данные из наших дублирующих таблиц в основные таблицы, используя ALTER TABLE MOVE PARTITION оператор.
Вышеуказанный вызов MOVE PARTITION использует имя раздела (). Это представляет единый раздел для этой таблицы (которая не разделена). Для таблиц, которые разделены, пользователям придется вызвать несколько MOVE PARTITION вызовов — по одному для каждого раздела. Имя текущих разделов можно определить из таблицы system.parts, например, SELECT DISTINCT partition FROM system.parts WHERE (table = 'pypi_v2').
Теперь мы можем подтвердить, что pypi и pypi_downloads содержат полные данные. pypi_downloads_v2 и pypi_v2 можно безопасно удалить.
Важно отметить, что операция MOVE PARTITION является легковесной (используя жесткие ссылки) и атомарной, т.е. она либо завершается неудачей, либо успехом без промежуточного состояния.
Мы активно используем этот процесс в наших сценариях заполнения ниже.
Обратите внимание, как этот процесс требует от пользователей выбирать размер каждой операции вставки.
Более крупные вставки, т.е. больше строк, будут означать меньшее количество MOVE PARTITION операций. Однако это должно быть сбалансировано с затратами в случае сбоя вставки, например, из-за прерывания сети, для восстановления. Пользователи могут дополнить этот процесс пакетированием файлов, чтобы снизить риск. Это можно выполнить любым из запросов диапазона, например, WHERE timestamp BETWEEN 2024-12-17 09:00:00 AND 2024-12-17 10:00:00, или используя шаблоны glob. Например,
ClickPipes использует этот подход при загрузке данных из объектного хранилища, автоматически создавая дубликаты целевой таблицы и ее материализованных представлений и избегая необходимости пользователю выполнять вышеуказанные шаги. Также используя несколько рабочих потоков, каждый из которых обрабатывает разные подмножества (через шаблоны glob) и имеет свои дублирующие таблицы, данные могут загружаться быстро с семантикой exactly-once. Для тех, кто интересуется, дополнительные подробности можно найти в этом блоге.
Сценарий 1: Заполнение данных с уже существующим приемом данных
В этом сценарии мы предполагаем, что данные для заполнения находятся не в изолированном бакете и, следовательно, требуется фильтрация. Данные уже вставляются, и можно идентифицировать временную метку или монотонно увеличивающийся столбец, из которого необходимо заполнить исторические данные.
Этот процесс включает следующие шаги:
- Определите контрольную точку — либо временную метку, либо значение столбца, с которого необходимо восстановить исторические данные.
- Создайте дубликаты основной таблицы и целевых таблиц для материализованных представлений.
- Создайте копии любых материализованных представлений, указывающих на целевые таблицы, созданные на шаге (2).
- Вставьте в нашу дублирующую таблицу, созданную на шаге (2).
- Переместите все разделы из дублирующих таблиц в их оригинальные версии. Удалите дублирующие таблицы.
Например, в наших данных PyPI предположим, что у нас уже есть загруженные данные. Мы можем определить минимальную временную метку, и, следовательно, нашу "контрольную точку".
Из вышеизложенного мы знаем, что нам нужно загрузить данные до 2024-12-17 09:00:00. Используя наш предыдущий процесс, мы создаем дублирующие таблицы и представления и загружаем подмножество, используя фильтр по временной метке.
Фильтрация по временным меткам в Parquet может быть очень эффективной. ClickHouse будет читать только столбец временной метки, чтобы определить полные диапазоны данных для загрузки, минимизируя сетевой трафик. Индексы Parquet, такие как min-max, также могут быть использованы движком запросов ClickHouse.
Как только эта вставка завершится, мы сможем переместить соответствующие разделы.
Если исторические данные находятся в изолированном бакете, вышеуказанный временной фильтр не требуется. Если временная или монотонная колонка недоступна, изолируйте свои исторические данные.
Пользователям ClickHouse Cloud следует использовать ClickPipes для восстановления исторических резервных копий, если данные могут быть изолированы в собственном бакете (и фильтр не требуется). Параллелизуя загрузку с помощью нескольких рабочих, что уменьшает время загрузки, ClickPipes автоматизирует вышеуказанный процесс — создавая дублирующие таблицы как для основной таблицы, так и для материализованных представлений.
Сценарий 2: Добавление материализованных представлений к существующим таблицам
Не uncommon, что новые материализованные представления необходимо добавлять к настройке, для которой уже были заполнены значительные данные и данные вставляются. Временная метка или монотонно увеличивающийся столбец, который можно использовать для идентификации точки в потоке, полезны здесь и позволяют избежать пауз в приеме данных. В примерах ниже мы предполагаем оба случая, предпочитая подходы, которые избегают пауз в вставке.
Мы не рекомендуем использовать команду POPULATE для заполнения материализованных представлений для чего-либо, кроме небольших наборов данных, когда прием приостанавливается. Этот оператор может пропустить строки, вставленные в исходную таблицу, с материализованным представлением, созданным после того, как заполнение хеш завершено. Кроме того, это заполнение выполняется по всем данным и подвержено прерыванию или ограничениям памяти для больших наборов данных.
Доступна временная метка или монотонно увеличивающийся столбец
В этом случае мы рекомендуем, чтобы новое материализованное представление включало фильтр, который ограничивает строки теми, которые превышают произвольные данные в будущем. Затем материализованное представление может быть заполнено с этой даты с использованием исторических данных из основной таблицы. Подход к заполнению зависит от размера данных и сложности связанного запроса.
Наш самый простой подход включает следующие шаги:
- Создайте наше материализованное представление с фильтром, который учитывает только строки, превышающие произвольное время в ближайшем будущем.
- Выполните запрос
INSERT INTO SELECT, который вставляет в целевую таблицу нашего материализованного представления, считывая из исходной таблицы с агрегирующим запросом представления.
Это можно дополнительно улучшить, нацелившись на подмножества данных на этапе (2) и/или использовать дублирующую целевую таблицу для материализованного представления (присоедините разделы к оригиналу, как только вставка завершится) для упрощения восстановления после сбоя.
Рассмотрим следующее материализованное представление, которое вычисляет самые популярные проекты за час.
Хотя мы можем добавить целевую таблицу, перед добавлением материализованного представления мы изменяем его SELECT предложение, чтобы включить фильтр, который учитывает только строки, превышающие произвольное время в ближайшем будущем — в этом случае мы предполагаем, что 2024-12-17 09:00:00 является ближайшим будущем.
Как только этот вид добавлен, мы можем заполнить все данные для материализованного представления до этой даты.
Простейший способ сделать это — просто выполнить запрос из материализованного представления на основной таблице с фильтром, который игнорирует недавно добавленные данные, вставляя результаты в целевую таблицу нашего представления через INSERT INTO SELECT. Например, для вышеуказанного представления:
В вышеуказанном примере наша целевая таблица является SummingMergeTree. В этом случае мы можем просто использовать наш оригинальный агрегирующий запрос. Для более сложных случаев использования, которые используют AggregatingMergeTree, пользователи будут использовать функции -State для агрегатов. Пример этого можно найти здесь.
В нашем случае это относительно легковесная агрегация, которая завершается менее чем за 3 секунды и использует менее 600MiB памяти. Для более сложных или долгосрочных агрегаций пользователи могут сделать этот процесс более устойчивым, используя ранее упомянутый подход с дублирующей таблицей, т.е. создайте целевую дублирующую таблицу, например pypi_downloads_per_day_v2, вставьте в нее и затем прикрепите получившиеся разделы к pypi_downloads_per_day.
Часто запрос материализованного представления может быть более сложным (что не редкость, иначе пользователи не стали бы использовать представления!) и потреблять ресурсы. В редких случаях ресурсы для запроса превышают возможности сервера. Это подчеркивает одно из преимуществ материализованных представлений ClickHouse — они инкрементальны и не обрабатывают весь набор данных за один раз!
В этом случае у пользователей есть несколько вариантов:
- Измените ваш запрос для заполнения диапазонов, например,
WHERE timestamp BETWEEN 2024-12-17 08:00:00 AND 2024-12-17 09:00:00,WHERE timestamp BETWEEN 2024-12-17 07:00:00 AND 2024-12-17 08:00:00и т.д. - Используйте движок таблицы Null для заполнения материализованного представления. Это воспроизводит типичную инкрементальную подпитку материализованного представления, выполняя его запрос по блокам данных (конфигурируемого размера).
(1) представляет собой самый простой подход и часто является достаточным. Мы не включаем примеры для краткости.
Мы исследуем (2) более подробно ниже.
Использование движка таблицы Null для заполнения материализованных представлений
Движок таблицы Null предоставляет движок хранения, который не сохраняет данные (думайте о нем как о /dev/null в мире движков таблиц). Хотя это кажется противоречивым, материализованные представления все равно выполняются на данных, вставленных в этот движок таблицы. Это позволяет строить материализованные представления, не сохраняя оригинальные данные, избегая ввода-вывода и сопутствующего хранения.
Важно, что любые материализованные представления, прикрепленные к движку таблицы, все равно выполняются по блокам данных, по мере их вставки — отправляя свои результаты в целевую таблицу. Эти блоки имеют конфигурируемый размер. Хотя более крупные блоки могут быть потенциально более эффективными (и быстрее в Processing), они расходуют больше ресурсов (прежде всего памяти). Использование этого движка таблицы означает, что мы можем создавать наше материализованное представление инкрементально, т.е. по одному блоку за раз, избегая необходимости удерживать всю агрегацию в памяти.
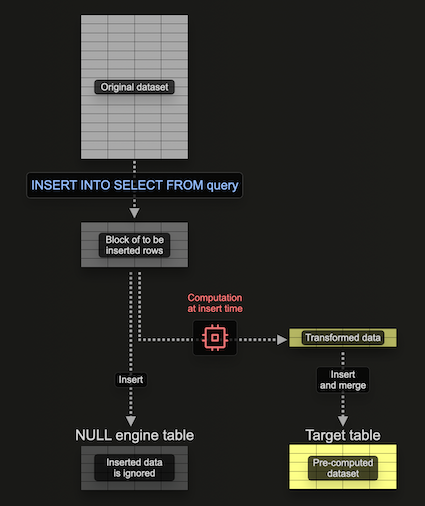
Рассмотрим следующий пример:
Здесь мы создаем таблицу Null, pypi_v2, чтобы получать строки, которые будут использоваться для построения нашего материализованного представления. Обратите внимание, как мы ограничиваем схему только необходимыми столбцами. Наше материализованное представление выполняет агрегацию по строкам, вставленным в эту таблицу (по одному блоку за раз), отправляя результаты в нашу целевую таблицу pypi_downloads_per_day.
Мы использовали pypi_downloads_per_day как нашу целевую таблицу здесь. Для дополнительной устойчивости пользователи могут создать дублирующую таблицу, pypi_downloads_per_day_v2, и использовать ее как целевую таблицу представления, как показано в предыдущих примерах. По завершении вставки разделы в pypi_downloads_per_day_v2 могут, в свою очередь, быть перемещены в pypi_downloads_per_day. Это позволит восстановить данные в случае, если наша вставка завершится неудачей из-за проблем памяти или сбоев сервера, т.е. мы просто усечем pypi_downloads_per_day_v2, настроим параметры и попробуем снова.
Чтобы заполнить это материализованное представление, мы просто вставляем соответствующие данные для заполнения в pypi_v2 из pypi.
Обратите внимание, что наше использование памяти здесь составляет 639.47 MiB.
Настройка производительности и ресурсов
Несколько факторов определят производительность и ресурсы, использованные в вышеупомянутом сценарии. Прежде чем пытаться настроить, мы рекомендуем читателям ознакомиться с механикой вставки, документированной подробно в разделе Использование потоков для чтения руководства Оптимизация для вставки и чтения в S3. В кратком изложении:
- Параллелизм чтения — количество потоков, используемых для чтения. Контролируется через
max_threads. В ClickHouse Cloud это определяется размером экземпляра, по умолчанию равным количеству vCPU. Увеличение этого значения может улучшить производительность чтения за счет большего использования памяти. - Параллелизм вставки — количество потоков вставки, используемых для вставки. Контролируется через
max_insert_threads. В ClickHouse Cloud это определяется размером экземпляра (от 2 до 4) и устанавливается на 1 в OSS. Увеличение этого значения может улучшить производительность за счет большего использования памяти. - Размер блока вставки — данные обрабатываются в цикле, где они извлекаются, разбираются и формируются в блоки вставки в памяти на основе ключа разбиения. Эти блоки сортируются, оптимизируются, сжимаются и записываются в хранилище как новые части данных. Размер блока вставки, контролируемый настройками
min_insert_block_size_rowsиmin_insert_block_size_bytes(несжатый), влияет на использование памяти и ввод-вывод диска. Более крупные блоки используют больше памяти, но создают меньше частей, уменьшая ввод-вывод и фоновое слияние. Эти настройки представляют собой минимальные пороговые значения (первое, которое будет достигнуто, вызовет сброс). - Размер блока материализованного представления — кроме механики для основной вставки, перед вставкой в материализованные представления блоки также упаковываются для более эффективной обработки. Размер этих блоков определяется настройками
min_insert_block_size_bytes_for_materialized_viewsиmin_insert_block_size_rows_for_materialized_views. Более крупные блоки позволяют более эффективную обработку за счет большего использования памяти. По умолчанию эти настройки возвращаются к значениям настроек исходной таблицыmin_insert_block_size_rowsиmin_insert_block_size_bytes, соответственно.
Для улучшения производительности пользователи могут следовать рекомендациям, изложенным в разделе Настройка потоков и размера блока для вставок руководства Оптимизация для вставки и чтения в S3. В большинстве случаев не должно быть необходимости изменить также min_insert_block_size_bytes_for_materialized_views и min_insert_block_size_rows_for_materialized_views, чтобы улучшить производительность. Если они изменяются, используйте те же лучшие практики, как описано для min_insert_block_size_rows и min_insert_block_size_bytes.
Чтобы минимизировать использование памяти, пользователи могут попробовать поэкспериментировать с этими настройками. Это неизбежно снизит производительность. Используя ранее указанный запрос, мы показываем ниже примеры.
Уменьшение max_insert_threads до 1 снижает нашу нагрузку на память.
Мы можем еще больше снизить память, установив настройку max_threads на 1.
Наконец, мы можем еще больше снизить память, установив min_insert_block_size_rows на 0 (отключает его как фактор принятия решения по размеру блока) и min_insert_block_size_bytes на 10485760 (10MiB).
Наконец, обратите внимание, что снижение размеров блока создает больше частей и вызывает большее давление на слияние. Как обсуждалось здесь, эти настройки следует изменять осторожно.
Нет временной метки или монотонно увеличивающегося столбца
При вышеуказанных процессах от пользователей требуется наличие временной метки или монотонно увеличивающегося столбца. В некоторых случаях это просто недоступно. В этом случае мы рекомендуем следующий процесс, который использует многие из шагов, описанных ранее, но требует от пользователей приостановить прием данных.
- Приостановите вставки в вашу основную таблицу.
- Создайте дубликат вашей целевой таблицы с помощью синтаксиса
CREATE AS. - Присоедините разделы из оригинальной целевой таблицы к дубликату с помощью
ALTER TABLE ATTACH. Примечание: Эта операция присоединения отличается от ранее использованного перемещения. Используя жесткие ссылки, данные в оригинальной таблице сохраняются. - Создайте новые материализованные представления.
- Перезапустите вставки. Примечание: Вставки будут обновлять только целевую таблицу, а не дубликат, который будет ссылаться только на оригинальные данные.
- Заполните материализованное представление, применяя тот же процесс, что и выше для данных с временными метками, используя дубликат таблицы в качестве источника.
Рассмотрим следующий пример с использованием PyPI и нашим предыдущим новым материализованным представлением pypi_downloads_per_day (предположим, что мы не можем использовать временную метку):
На предпоследнем шаге мы заполняем pypi_downloads_per_day с использованием нашего простого подхода INSERT INTO SELECT, описанного ранее. Это также может быть улучшено с использованием подхода с Null таблицей, документированным выше, с дополнительным использованием дубликатной таблицы для большей устойчивости.
Хотя эта операция требует приостановки вставок, промежуточные операции могут обычно быть выполнены быстро, минимизируя любые перерывы в данных.