Разделение Хранения и Вычислений
Обзор
Этот гид рассматривает, как можно использовать ClickHouse и S3 для реализации архитектуры с разделенным хранением и вычислениями.
Разделение хранения и вычислений означает, что вычислительные ресурсы и ресурсы хранения управляются независимо. В ClickHouse это позволяет добиться лучшей масштабируемости, экономии затрат и гибкости. Вы можете масштабировать ресурсы хранения и вычислений отдельно по мере необходимости, оптимизируя производительность и расходы.
Использование ClickHouse с поддержкой S3 особенно полезно для тех случаев, когда производительность запросов к "холодным" данным менее критична. ClickHouse поддерживает использование S3 в качестве хранилища для движка MergeTree с использованием S3BackedMergeTree. Этот движок таблиц позволяет пользователям использовать преимущества масштабируемости и экономии затрат S3, сохраняя производительность вставки и запросов движка MergeTree.
Обратите внимание, что реализация и управление архитектурой с разделенным хранением и вычислениями более сложны по сравнению со стандартными развертываниями ClickHouse. Хотя самоуправляемый ClickHouse позволяет разделять хранение и вычисления, как обсуждается в этом гиде, мы рекомендуем использовать ClickHouse Cloud, который позволяет вам использовать ClickHouse в этой архитектуре без конфигурации с помощью табличного движка SharedMergeTree.
Этот гид предполагает, что вы используете версию ClickHouse 22.8 или выше.
Не настраивайте никакую политику жизненного цикла AWS/GCS. Это не поддерживается и может привести к повреждению таблиц.
1. Используйте S3 в качестве диска ClickHouse
Создание диска
Создайте новый файл в директории ClickHouse config.d для хранения конфигурации хранения:
Скопируйте следующий XML в только что созданный файл, заменив BUCKET, ACCESS_KEY_ID, SECRET_ACCESS_KEY на детали AWS-бакета, в котором вы хотите хранить ваши данные:
Если вам нужно дополнительно задать настройки для диска S3, например, указать region или отправить пользовательский HTTP header, вы можете найти список соответствующих настроек здесь.
Вы также можете заменить access_key_id и secret_access_key на следующее, что попытается получить учетные данные из переменных окружения и метаданных Amazon EC2:
После того как вы создали файл конфигурации, вам нужно обновить владельца файла на пользователя и группу clickhouse:
Теперь вы можете перезапустить сервер ClickHouse, чтобы изменения вступили в силу:
2. Создание таблицы с поддержкой S3
Чтобы проверить, правильно ли мы настроили диск S3, мы можем попытаться создать и выполнить запрос к таблице.
Создайте таблицу, указав новую политику хранения S3:
Обратите внимание, что нам не нужно было указывать движок как S3BackedMergeTree. ClickHouse автоматически преобразует тип движка на внутреннем уровне, если он обнаруживает, что таблица использует S3 для хранения.
Проверьте, что таблица была создана с правильной политикой:
Вы должны увидеть следующий результат:
Теперь давайте вставим несколько строк в нашу новую таблицу:
Проверим, что наши строки были добавлены:
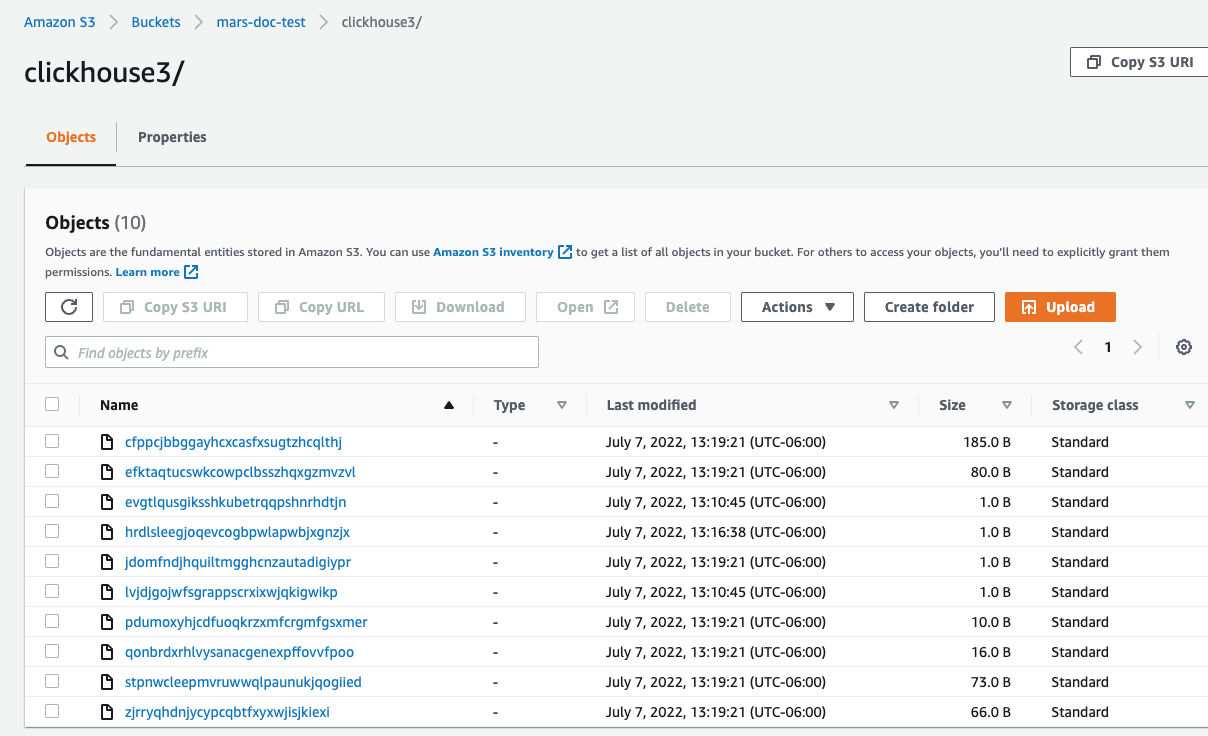
В консоли AWS, если ваши данные успешно вставлены в S3, вы должны увидеть, что ClickHouse создал новые файлы в вашем указанном бакете.
Если все прошло успешно, теперь вы используете ClickHouse с разделенным хранением и вычислениями!
3. Реализация репликации для отказоустойчивости (необязательно)
Не настраивайте никакую политику жизненного цикла AWS/GCS. Это не поддерживается и может привести к повреждению таблиц.
Для обеспечения отказоустойчивости вы можете использовать несколько узлов сервера ClickHouse, распределенных по нескольким регионам AWS, с бакетом S3 для каждого узла.
Репликация с использованием дисков S3 может быть достигнута с помощью движка таблиц ReplicatedMergeTree. См. следующий гид для деталей: