Использование движка таблицы Kafka
Движок таблицы Kafka не поддерживается в ClickHouse Cloud. Пожалуйста, рассмотрите ClickPipes или Kafka Connect
Kafka в ClickHouse
Для использования движка таблицы Kafka вам следует быть в основном знакомым с материализованными представлениями ClickHouse.
Обзор
Сначала мы сосредоточимся на самом распространенном сценарии: использовании движка таблицы Kafka для вставки данных в ClickHouse из Kafka.
Движок таблицы Kafka позволяет ClickHouse читать данные напрямую из темы Kafka. Хотя это полезно для просмотра сообщений в теме, движок по своему дизайну допускает только одноразовое извлечение, т.е. когда запрос отправляется к таблице, он потребляет данные из очереди и увеличивает смещение потребителя, прежде чем вернуть результаты вызывающему. Данные не могут быть повторно прочитаны без сброса этих смещений.
Для постоянного хранения этих данных из чтения движка таблицы нам необходимо средство для захвата данных и вставки их в другую таблицу. Материализованные представления, основанные на триггерах, предоставляют эту функциональность. Материализованное представление инициирует чтение из движка таблицы, получая пакеты документов. В конструкции TO указывается цель данных - обычно это таблица из семейства Merge Tree. Этот процесс визуализируется ниже:
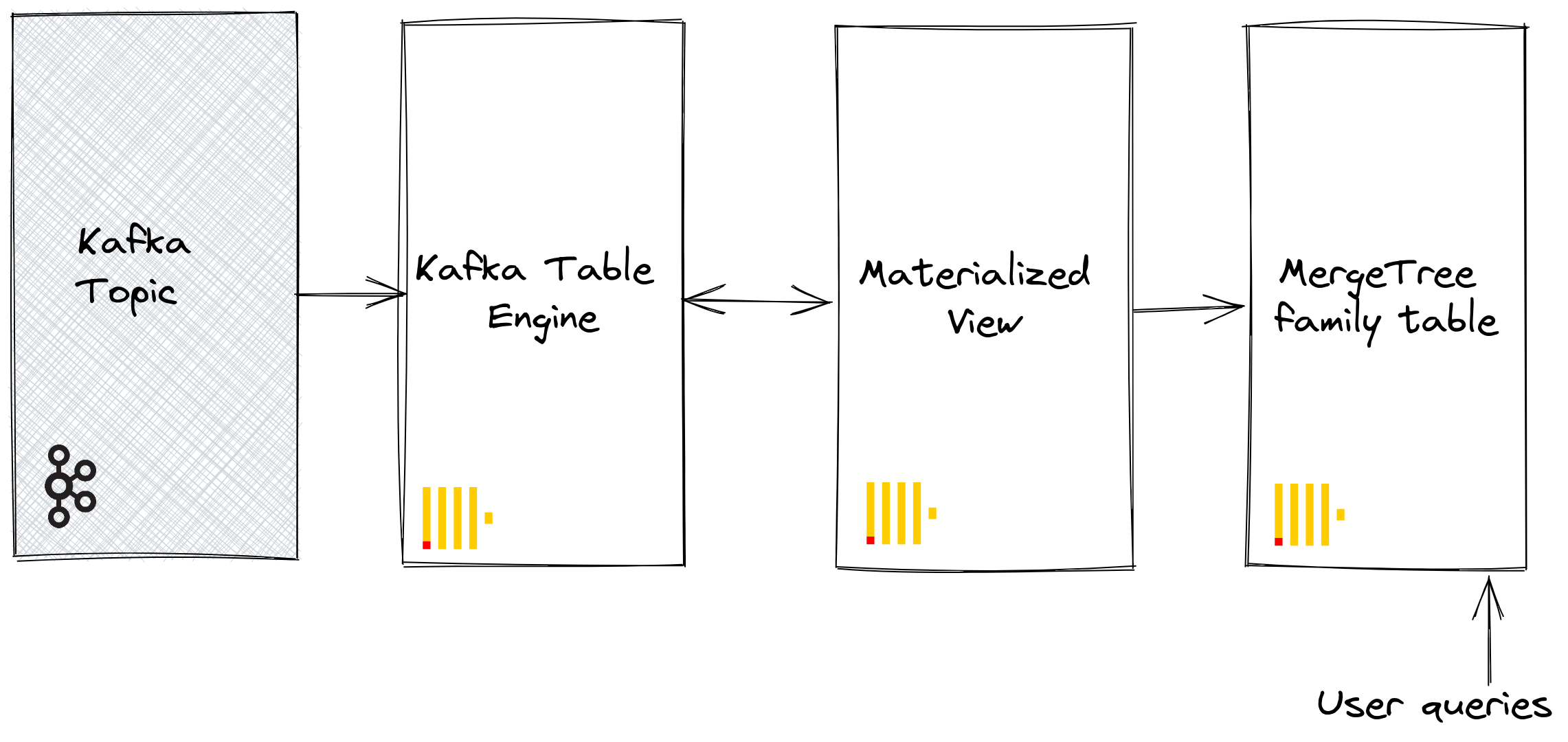
Шаги
1. Подготовка
Если вы уже имеете данные на целевой теме, вы можете адаптировать следующее для использования в вашем наборе данных. В качестве альтернативы, образец набора данных GitHub предоставлен здесь. Этот набор данных используется в примерах ниже и использует сокращенную схему и подмножество строк (в частности, мы ограничиваемся событиями GitHub, касающимися репозитория ClickHouse), по сравнению с полным набором данных, доступным здесь, ради краткости. Это все еще достаточно для работы большинства запросов опубликованных с набором данных.
2. Настройка ClickHouse
Этот шаг требуется, если вы подключаетесь к защищенному Kafka. Эти настройки не могут быть переданы через команды SQL DDL и должны быть настроены в config.xml ClickHouse. Мы предполагаем, что вы подключаетесь к экземпляру с защищенным SASL. Это самый простой метод при работе с Confluent Cloud.
Поместите приведенный выше фрагмент в новый файл в каталоге conf.d/ или объедините его с существующими конфигурационными файлами. Для настроек, которые можно настроить, смотрите здесь.
Мы также создадим базу данных с именем KafkaEngine, которую будем использовать в этом учебнике:
После создания базы данных вам нужно переключиться на нее:
3. Создайте целевую таблицу
Подготовьте свою целевую таблицу. В примере ниже мы используем сокращенную схему GitHub для краткости. Обратите внимание, что хотя мы используем движок таблицы MergeTree, этот пример можно легко адаптировать для любого члена семейства MergeTree.
4. Создайте и заполните тему
Далее мы создадим тему. Существует несколько инструментов, которые мы можем использовать для этого. Если мы запускаем Kafka локально на нашем компьютере или в контейнере Docker, RPK работает хорошо. Мы можем создать тему с именем github с 5 партициями, запустив следующую команду:
Если мы запускаем Kafka в Confluent Cloud, мы можем предпочесть использовать Confluent CLI:
Теперь нам нужно заполнить эту тему некоторыми данными, что мы и сделаем с помощью kcat. Мы можем выполнить команду, аналогичную следующей, если мы запускаем Kafka локально с отключенной аутентификацией:
Или следующую, если наш кластер Kafka использует SASL для аутентификации:
Набор данных содержит 200,000 строк, поэтому он должен быть загружен всего за несколько секунд. Если вы хотите работать с более крупным набором данных, обратите внимание на раздел больших наборов данных репозитория ClickHouse/kafka-samples.
5. Создайте движок таблицы Kafka
Приведенный ниже пример создает движок таблицы с той же схемой, что и таблица MergeTree. Это не является строгим требованием, поскольку вы можете иметь псевдонимы или эфемерные столбцы в целевой таблице. Тем не менее, настройки важны; обратите внимание на использование JSONEachRow в качестве типа данных для потребления JSON из темы Kafka. Значения github и clickhouse представляют собой имя темы и имена групп потребителей соответственно. Темы могут на самом деле быть списком значений.
Ниже мы обсуждаем настройки движка и оптимизацию производительности. На этом этапе простое выполнение запроса select на таблице github_queue должно прочитать некоторые строки. Обратите внимание, что это переместит смещения потребителей вперед, что предотвратит повторное чтение этих строк без сброса. Обратите внимание на лимит и обязательный параметр stream_like_engine_allow_direct_select.
6. Создайте материализованное представление
Материализованное представление соединит две ранее созданные таблицы, считывая данные из движка таблицы Kafka и вставляя их в целевую таблицу MergeTree. Мы можем выполнить ряд преобразований данных. Мы сделаем простое чтение и вставку. Использование * предполагает, что имена столбцов идентичны (чувствительно к регистру).
В момент создания материализованное представление подключается к движку Kafka и начинает чтение: вставляя строки в целевую таблицу. Этот процесс будет продолжаться бесконечно, при этом последующие вставки сообщений в Kafka будут потребляться. Не стесняйтесь повторно выполнять сценарий вставки, чтобы вставить дополнительные сообщения в Kafka.
7. Подтвердите, что строки были вставлены
Подтвердите наличие данных в целевой таблице:
Вы должны увидеть 200,000 строк:
Основные операции
Остановка и перезапуск потребления сообщений
Чтобы остановить потребление сообщений, вы можете отсоединить таблицу движка Kafka:
Это не повлияет на смещения группы потребителей. Чтобы перезапустить потребление и продолжить с предыдущего смещения, повторно подключите таблицу.
Добавление метаданных Kafka
Полезно отслеживать метаданные из оригинальных сообщений Kafka после их загрузки в ClickHouse. Например, мы можем захотеть знать, сколько определенной темы или партиции мы потребили. Для этой цели движок таблицы Kafka предоставляет несколько виртуальных столбцов. Эти столбцы могут быть сохранены в нашей целевой таблице, изменив нашу схему и оператор select материализованного представления.
Сначала выполняем операцию остановки, описанную выше, перед добавлением столбцов в нашу целевую таблицу.
Ниже мы добавляем информационные столбцы, чтобы определить исходную тему и партицию, откуда появилась строка.
Затем мы должны убедиться, что виртуальные столбцы сопоставлены как необходимо.
Виртуальные столбцы начинаются с символа _.
Полный список виртуальных столбцов можно найти здесь.
Чтобы обновить нашу таблицу с виртуальными столбцами, нам нужно удалить материализованное представление, повторно подключить таблицу движка Kafka и заново создать материализованное представление.
Сначала потребленные строки должны содержать метаданные.
Результат выглядит так:
| actor_login | event_type | created_at | topic | partition |
|---|---|---|---|---|
| IgorMinar | CommitCommentEvent | 2011-02-12 02:22:00 | github | 0 |
| queeup | CommitCommentEvent | 2011-02-12 02:23:23 | github | 0 |
| IgorMinar | CommitCommentEvent | 2011-02-12 02:23:24 | github | 0 |
| IgorMinar | CommitCommentEvent | 2011-02-12 02:24:50 | github | 0 |
| IgorMinar | CommitCommentEvent | 2011-02-12 02:25:20 | github | 0 |
| dapi | CommitCommentEvent | 2011-02-12 06:18:36 | github | 0 |
| sourcerebels | CommitCommentEvent | 2011-02-12 06:34:10 | github | 0 |
| jamierumbelow | CommitCommentEvent | 2011-02-12 12:21:40 | github | 0 |
| jpn | CommitCommentEvent | 2011-02-12 12:24:31 | github | 0 |
| Oxonium | CommitCommentEvent | 2011-02-12 12:31:28 | github | 0 |
Изменение настроек движка Kafka
Мы рекомендуем удалить таблицу движка Kafka и заново создать ее с новыми настройками. Материализованное представление не нужно изменять в этот процесс - потребление сообщений возобновится, как только таблица движка Kafka будет воссоздана.
Отладка проблем
Ошибки, такие как проблемы аутентификации, не сообщаются в ответах на DDL движка Kafka. Для диагностики проблем мы рекомендуем использовать основной файл журнала ClickHouse clickhouse-server.err.log. Дополнительное трассировочное логирование для библиотеки клиентского интерфейса Kafka librdkafka можно включить через конфигурацию.
Обработка неправильно сформированных сообщений
Kafka часто используется как "свалка" для данных. Это приводит к тому, что темы содержат смешанные форматы сообщений и несогласованные имена полей. Избегайте этого и воспользуйтесь функциями Kafka, такими как Kafka Streams или ksqlDB, чтобы гарантировать, что сообщения хорошо сформированы и согласованны перед их вставкой в Kafka. Если эти варианты невозможны, ClickHouse имеет некоторые функции, которые могут помочь.
- Рассматривайте поле сообщения как строки. Можно использовать функции в операторе материализованного представления для очистки и приведения типов, если это необходимо. Это не должно представлять собой решение для производства, но может помочь в единовременной загрузке.
- Если вы потребляете JSON из темы, используя формат JSONEachRow, используйте настройку
input_format_skip_unknown_fields. При записи данных, по умолчанию ClickHouse выбрасывает исключение, если входные данные содержат столбцы, которые не существуют в целевой таблице. Однако, если эта опция включена, эти избыточные столбцы будут игнорироваться. Опять же, это не решение для производственного уровня и может ввести других в заблуждение. - Рассмотрите настройку
kafka_skip_broken_messages. Это требует от пользователя указания уровня допустимости для каждого блока на случай неправильно сформированных сообщений - рассматриваемый в контексте kafka_max_block_size. Если это допустимое значение превышено (измеряется в абсолютных сообщениях), поведение исключений вернется к обычному, и другие сообщения будут пропущены.
Семантика доставки и проблемы с дубликатами
Движок таблицы Kafka имеет семантику как минимум один раз. Дубликаты возможны в нескольких известных редких обстоятельствах. Например, сообщения могут быть прочитаны из Kafka и успешно вставлены в ClickHouse. Прежде чем новое смещение может быть зафиксировано, соединение с Kafka теряется. В этой ситуации требуется повторная попытка блока. Блок может быть дедуплицирован, используя распределенную таблицу или ReplicatedMergeTree в качестве целевой таблицы. Хотя это уменьшает вероятность появления дублирующих строк, это зависит от идентичных блоков. События, такие как перераспределение Kafka, могут аннулировать это предположение, вызывая дубликаты в редких случаях.
Вставки на основе кворума
Вам могут понадобиться вставки на основе кворума в случаях, когда в ClickHouse требуются более высокие гарантии доставки. Это не может быть установлено на материализованное представление или целевую таблицу. Однако это можно установить для профилей пользователей, например.
ClickHouse в Kafka
Хотя это реже встречающийся сценарий, данные ClickHouse также могут быть сохранены в Kafka. Например, мы будем вручную вставлять строки в движок таблицы Kafka. Эти данные будут считываться тем же движком Kafka, чье материализованное представление поместит данные в таблицу Merge Tree. В конце концов, мы продемонстрируем применение материализованных представлений в вставках в Kafka, чтобы читать таблицы из существующих исходных таблиц.
Шаги
Наша первоначальная цель иллюстрируется следующим образом:
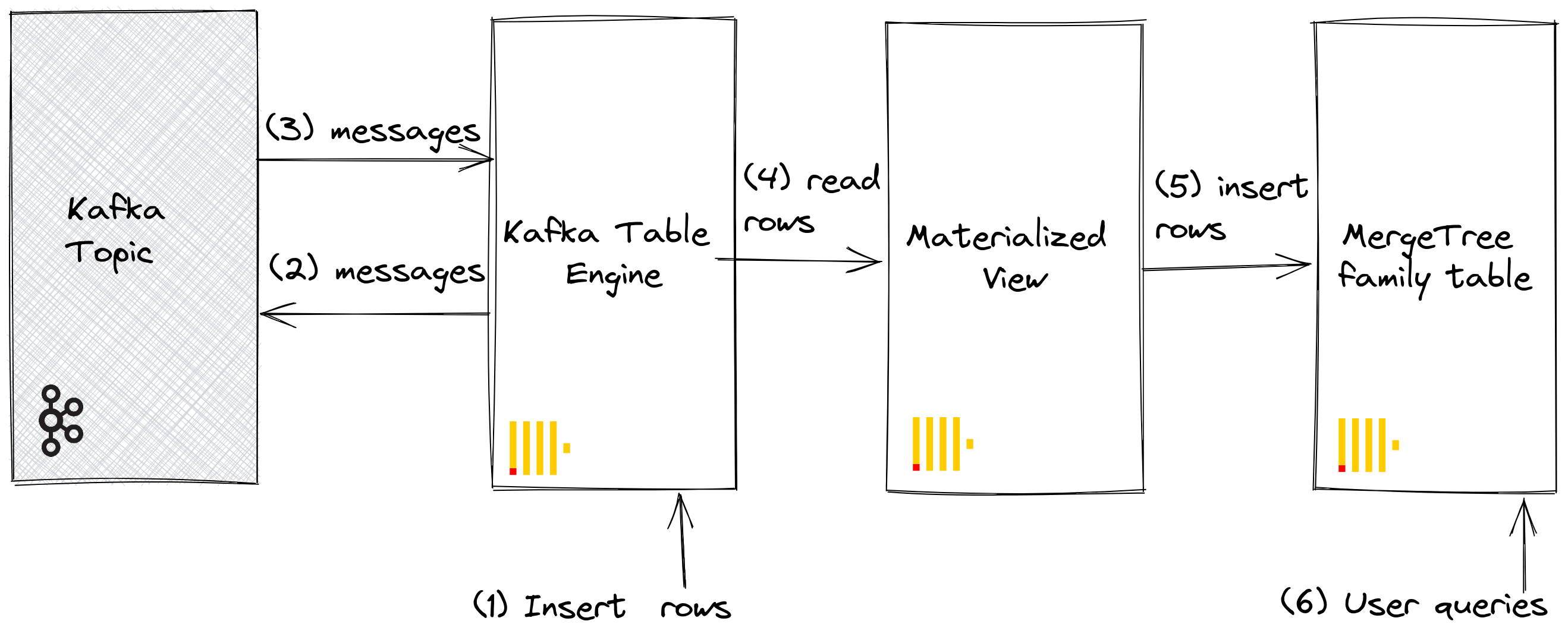
Мы предполагаем, что вы создали таблицы и представления в шагах для Kafka в ClickHouse и что тема была полностью потреблена.
1. Прямые вставки строк
Во-первых, подтвердите количество строк в целевой таблице.
У вас должно быть 200,000 строк:
Теперь вставим строки из целевой таблицы GitHub обратно в движок таблицы Kafka github_queue. Обратите внимание, как мы используем формат JSONEachRow и ограничиваем выборку до 100.
Пересчитайте строки в GitHub, чтобы подтвердить, что их количество увеличилось на 100. Как показано на вышеупомянутой диаграмме, строки были вставлены в Kafka через движок таблицы Kafka, прежде чем быть прочитанными тем же движком и вставленными в целевую таблицу GitHub через наше материализованное представление!
Вы должны увидеть еще 100 строк:
2. Использование материализованных представлений
Мы можем использовать материализованные представления, чтобы отправлять сообщения в движок Kafka (и тему), когда документы вставляются в таблицу. Когда строки вставляются в таблицу GitHub, срабатывает материализованное представление, благодаря которому строки вставляются обратно в движок Kafka и в новую тему. Опять же, это лучше всего иллюстрируется:
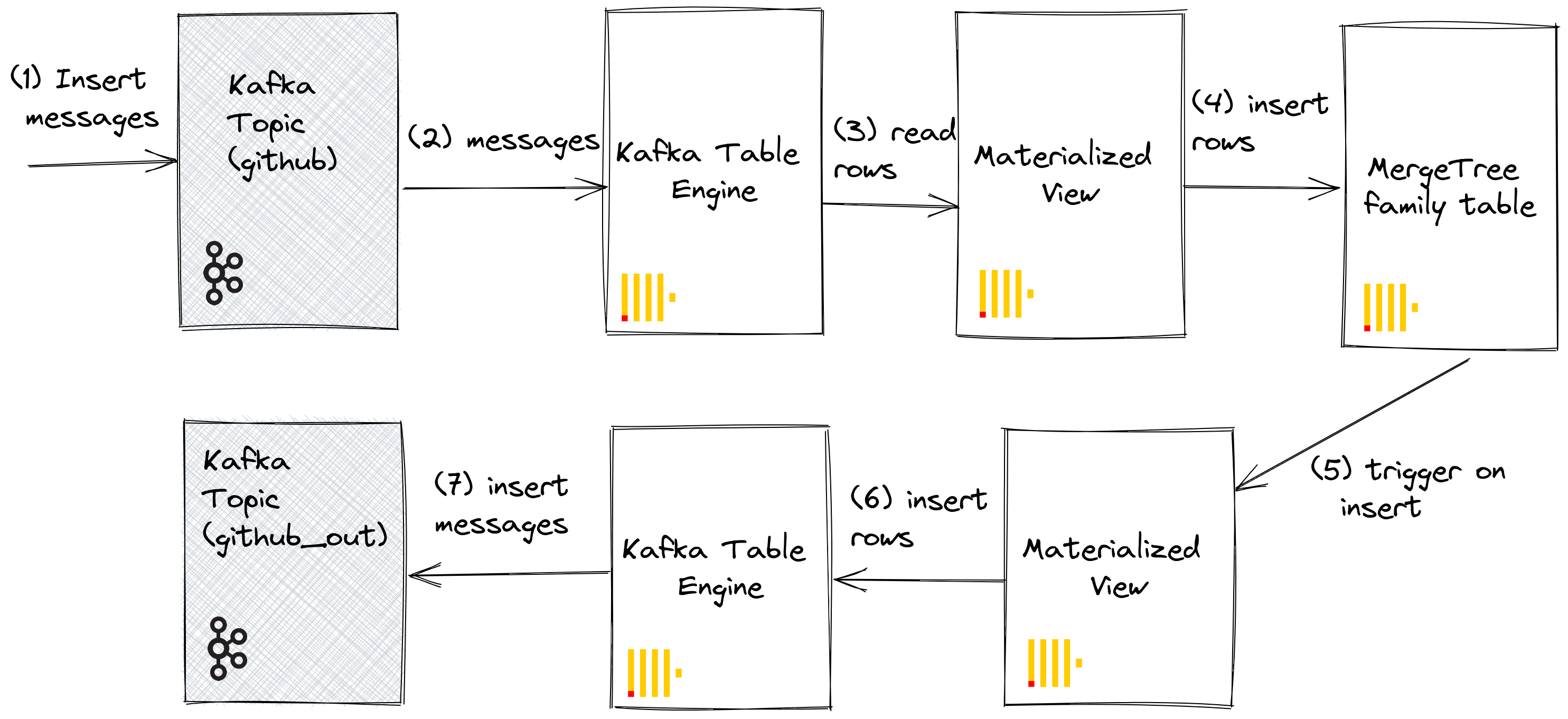
Создайте новую тему Kafka github_out или эквивалентную. Убедитесь, что движок таблицы Kafka github_out_queue указывает на эту тему.
Теперь создайте новое материализованное представление github_out_mv, чтобы оно указывало на таблицу GitHub и вставляло строки в вышеуказанный движок, когда оно срабатывает. Добавления в таблицу GitHub, таким образом, будут отправляться в нашу новую тему Kafka.
Если вы вставите в оригинальную тему github, созданную в рамках Kafka в ClickHouse, документы волшебным образом появятся в теме "github_clickhouse". Подтвердите это с помощью родных инструментов Kafka. Например, ниже мы вставляем 100 строк в тему github, используя kcat для темы, размещенной в Confluent Cloud:
Чтение из темы github_out должно подтвердить доставку сообщений.
Хотя это сложный пример, он иллюстрирует мощность материализованных представлений при использовании в сочетании с движком Kafka.
Кластеры и производительность
Работа с кластерами ClickHouse
Через группы потребителей Kafka несколько экземпляров ClickHouse могут потенциально читать из одной и той же темы. Каждому потребителю будет назначена партиция темы в 1:1. При расширении потребления ClickHouse с использованием движка таблицы Kafka учитывайте, что общее количество потребителей в кластере не может превышать количество партиций в теме. Поэтому заранее убедитесь, что партиционирование настроено правильно для темы.
Несколько экземпляров ClickHouse могут быть настроены для чтения из темы, используя один и тот же идентификатор группы потребителей, который указывается при создании движка таблицы Kafka. Таким образом, каждый экземпляр будет читать из одной или нескольких партиций, вставляя сегменты в свои локальные целевые таблицы. Целевые таблицы можно, в свою очередь, настроить для использования ReplicatedMergeTree, чтобы управлять дублированием данных. Этот подход позволяет масштабировать чтения Kafka с кластером ClickHouse, при условии наличия достаточного количества партиций Kafka.
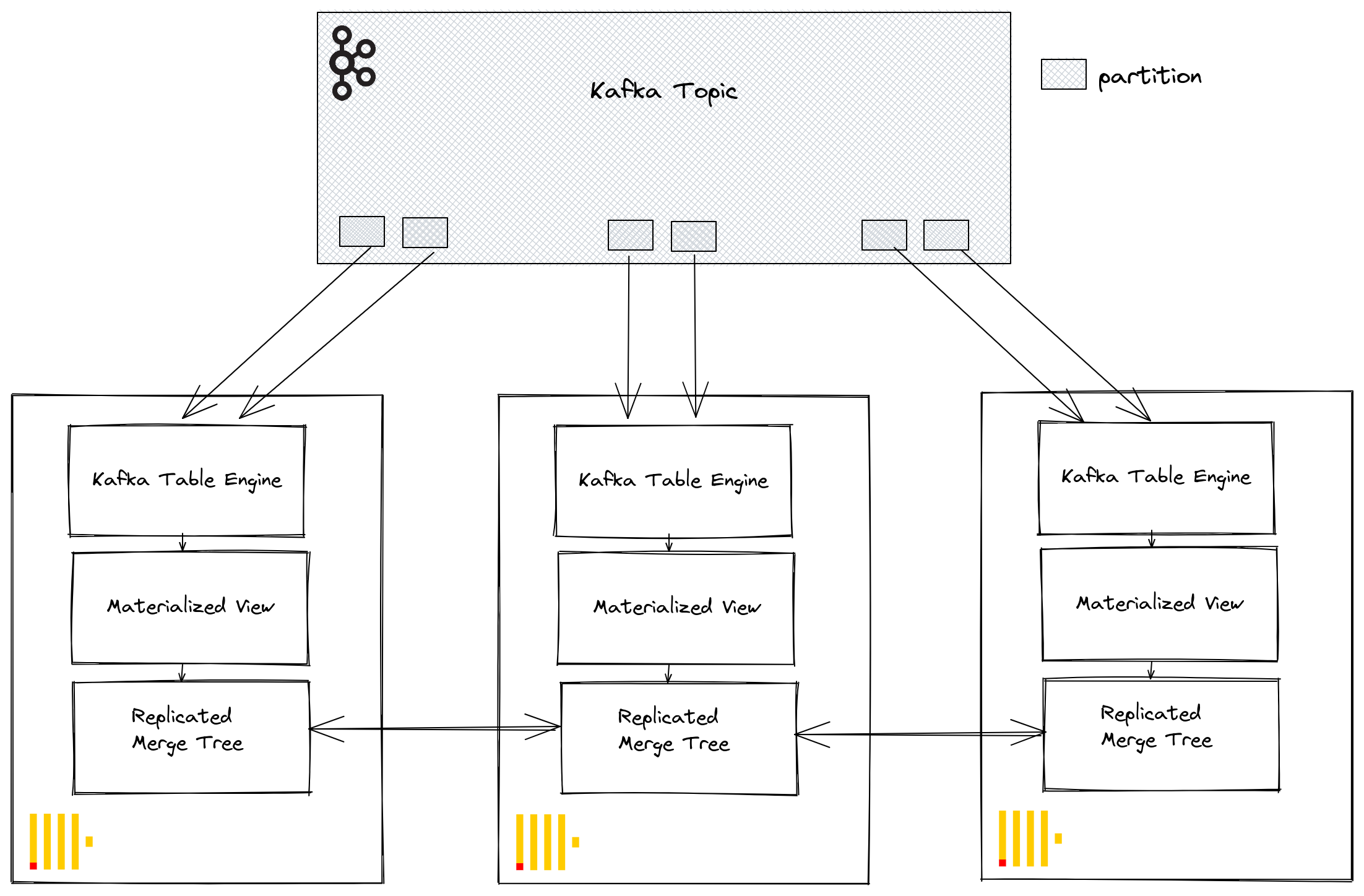
Оптимизация производительности
Учитывайте следующее, когда хотите увеличить производительность обработки таблицы движка Kafka:
- Производительность будет варьироваться в зависимости от размера сообщений, формата и типов целевых таблиц. 100k строк/с на одном движке таблицы следует считать достижимым. По умолчанию сообщения читаются блоками, контролируемыми параметром kafka_max_block_size. По умолчанию он установлен на max_insert_block_size, по умолчанию равный 1,048,576. Если сообщения не очень большие, его почти всегда следует увеличить. Значения между 500k и 1M не являются редкостью. Проверьте и оцените влияние на производительность.
- Количество потребителей для двигателя таблицы можно увеличить с помощью kafka_num_consumers. Тем не менее, по умолчанию вставки будут линейно упорядочены в одном потоке, если kafka_thread_per_consumer не будет изменен от значения по умолчанию, равного 1. Установите это значение на 1, чтобы гарантировать, что сбросы выполняются параллельно. Обратите внимание, что создание таблицы движка Kafka с N потребителями (и kafka_thread_per_consumer=1) логически эквивалентно созданию N движков Kafka, каждый с материализованным представлением и kafka_thread_per_consumer=0.
- Увеличение числа потребителей не является бесплатной операцией. Каждый потребитель поддерживает свои собственные буферы и потоки, увеличивая нагрузку на сервер. Будьте внимательны к накладным расходам потребителей и сначала масштабируйте линейно по вашему кластеру, если это возможно.
- Если пропускная способность сообщений Kafka переменна и задержки допустимы, рассмотрите возможность увеличения stream_flush_interval_ms для обеспеченияFlush больших блоков.
- background_message_broker_schedule_pool_size устанавливает количество потоков, выполняющих фоновые задачи. Эти потоки используются для стриминга Kafka. Эта настройка применяется при запуске сервера ClickHouse и не может быть изменена в пользовательской сессии, по умолчанию равной 16. Если вы видите тайм-ауты в журналах, возможно, стоит увеличить это число.
- Для связи с Kafka используется библиотека librdkafka, которая сама создает потоки. Большое количество таблиц Kafka или потребителей может привести к большому количеству переключений контекста. Либо распределите эту нагрузку по кластеру, дублируя целевые таблицы, если возможно, либо рассмотрите возможность использования движка таблицы для чтения из нескольких тем - поддерживается список значений. В нескольких материализованных представлениях можно читать из одной таблицы, каждый из которых фильтрует данные из конкретной темы.
Любые изменения настроек должны быть протестированы. Мы рекомендуем отслеживать отставание потребителей Kafka, чтобы убедиться, что вы правильно масштабированы.
Дополнительные настройки
Помимо обсужденных выше настроек, следующие могут быть интересны:
- Kafka_max_wait_ms - Время ожидания в миллисекундах для чтения сообщений из Kafka перед повторной попыткой. Устанавливается на уровне профиля пользователя и по умолчанию составляет 5000.
Все настройки из подлежащей библиотеки librdkafka также могут быть размещены в конфигурационных файлах ClickHouse внутри элемента kafka - имена настроек должны быть XML-элементами с точками, замененными на подчеркивания, например:
Это настройки для специалистов, и мы бы предложили вам обратиться к документации Kafka для более подробного объяснения.