Техники моделирования данных
Это Часть 3 руководства по миграции с PostgreSQL на ClickHouse. Этот контент можно считать вводным, с целью помочь пользователям развернуть начальную функциональную систему, которая соответствует лучшим практикам ClickHouse. Он избегает сложных тем и не приведет к полностью оптимизированной схеме; скорее, он предоставляет надежную основу для пользователей, чтобы построить продакшен-систему и базировать свое обучение.
Мы рекомендуем пользователям, мигрирующим с Postgres, прочитать руководство по моделированию данных в ClickHouse. Это руководство использует тот же набор данных из Stack Overflow и исследует несколько подходов с использованием возможностей ClickHouse.
Партиционирование
Пользователи Postgres будут знакомы с концепцией партиционирования таблиц для повышения производительности и управляемости больших баз данных, деля таблицы на более мелкие, более управляемые части, называемые партициями. Это партиционирование может быть достигнуто с помощью диапазона по определенному столбцу (например, даты), определенных списков или через хеш по ключу. Это позволяет администраторам организовывать данные на основе конкретных критериев, таких как диапазоны дат или географические локации. Партиционирование помогает улучшить производительность запросов, позволяя более быстрый доступ к данным через обрезку партиций и более эффективное индексирование. Это также помогает в задачах обслуживания, таких как резервное копирование и очистка данных, позволяя выполнять операции только над отдельными партициями, а не всей таблицей. Кроме того, партиционирование может значительно улучшить масштабируемость баз данных PostgreSQL, распределяя нагрузку по нескольким партициям.
В ClickHouse партиционирование указывается на таблице, когда она изначально определяется через оператор PARTITION BY. Этот оператор может содержать SQL-выражение по любым столбцам, результаты которого определяют, в какую партицию будет отправлена строка.
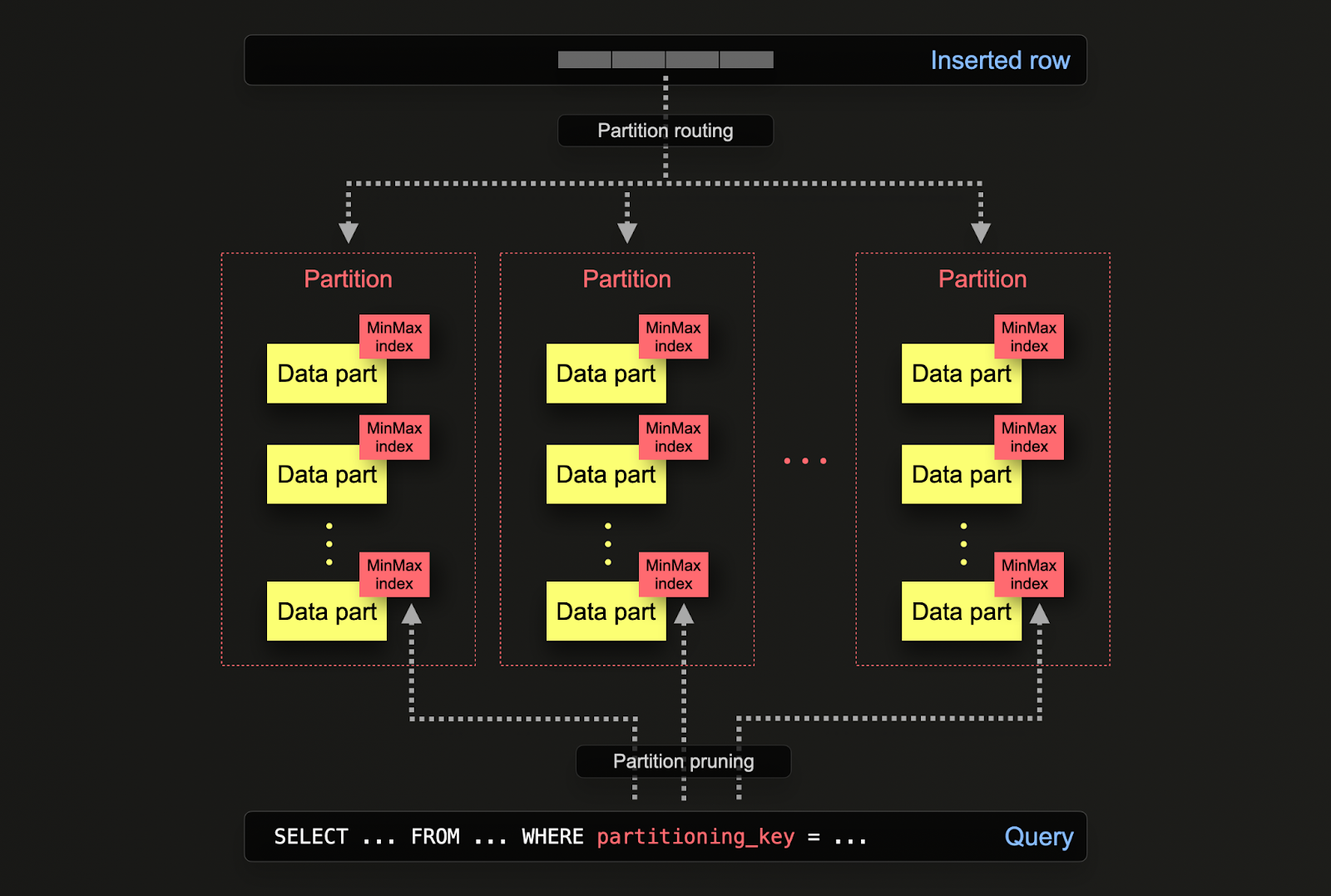
Части данных логически связаны с каждой партицией на диске и могут запрашиваться в изоляции. В следующем примере мы партиционируем таблицу posts по годам с использованием выражения toYear(CreationDate). По мере вставки строк в ClickHouse это выражение будет оцениваться для каждой строки и направляться в соответствующую партицию, если она существует (если строка является первой для года, партиция будет создана).
Применения партиций
Партиционирование в ClickHouse имеет аналогичные применения, как и в Postgres, но с некоторыми тонкими отличиями. Более конкретно:
- Управление данными - В ClickHouse пользователи должны в первую очередь рассматривать партиционирование как функцию управления данными, а не технику оптимизации запросов. Разделяя данные логически по ключу, каждая партиция может обрабатываться независимо, например, удаляться. Это позволяет пользователям перемещать партиции, а значит, подсеты, между уровнями хранения эффективно по времени или истекать данные/эффективно удалять из кластера. В примере ниже мы удаляем посты с 2008 года.
- Оптимизация запросов - Хотя партиции могут помочь с производительностью запросов, это сильно зависит от шаблонов доступа. Если запросы нацелены только на несколько партиций (желательно одну), производительность потенциально может улучшиться. Это только обычно полезно, если ключ партиционирования не входит в первичный ключ и вы фильтруете по нему. Однако запросы, которые должны охватывать множество партиций, могут работать хуже, чем если бы использование партиционирования не применялось (так как в результате партиционирования может быть больше частей). Преимущество таргетирования одной партиции будет еще менее вероятным или вообще отсутствовать, если ключ партиционирования уже является ранним элементом в первичном ключе. Партиционирование также может использоваться для оптимизации запросов GROUP BY, если значения в каждой партиции уникальны. Однако, в общем, пользователи должны убедиться, что первичный ключ оптимизирован и рассматривать партиционирование как технику оптимизации запросов лишь в исключительных случаях, когда шаблоны доступа обращаются к определенному предсказуемому подмножеству дня, например, партиционирование по дням, с большинством запросов в последний день.
Рекомендации по партициям
Пользователи должны рассматривать партиционирование как технику управления данными. Это идеально, когда данные должны быть истекшими из кластера при работе с временными рядами данных, например, самая старая партиция может просто быть удалена.
Важно: Убедитесь, что ваше выражение ключа партиционирования не приводит к множеству с высокой кардинальностью, т.е. создание более 100 партиций следует избегать. Например, не партиционируйте свои данные по столбцам с высокой кардинальностью, таким как идентификаторы клиентов или имена. Вместо этого сделайте идентификатор клиента или имя первым столбцом в выражении ORDER BY.
Внутри ClickHouse создает части для вставленных данных. По мере вставки большего количества данных количество частей увеличивается. Чтобы предотвратить чрезмерно высокое количество частей, что ухудшит производительность запросов (большее количество файлов для чтения), части объединяются в фоновом асинхронном процессе. Если количество частей превышает заранее настроенный предел, ClickHouse выбросит исключение при вставке - как ошибка "слишком много частей". Это не должно происходить в нормальных условиях и происходит только если ClickHouse неправильно настроен или используется неправильно, например, при большом количестве мелких вставок.
Поскольку части создаются для каждой партиции в изоляции, увеличение количества партиций приводит к увеличению количества частей, то есть оно является кратным количеству партиций. Ключи партиционирования с высокой кардинальностью могут, таким образом, причинять эту ошибку и должны быть избегаемы.
Материализованные представления vs проекции
Postgres позволяет создавать несколько индексов на одной таблице, что позволяет оптимизировать различные шаблоны доступа. Эта гибкость позволяет администраторам и разработчикам настраивать производительность базы данных под конкретные запросы и операционные нужды. Концепция проекций в ClickHouse, хотя и не полностью аналогична этому, позволяет пользователям указывать несколько операторов ORDER BY для таблицы.
В документации по моделированию данных ClickHouse мы исследуем, как материализованные представления могут быть использованы в ClickHouse для предварительного вычисления агрегаций, преобразования строк и оптимизации запросов для различных шаблонов доступа.
Для последнего из них мы предоставили пример, где материализованное представление отправляет строки в целевую таблицу с другим ключом сортировки, чем у оригинальной таблицы, принимающей вставки.
Например, рассмотрим следующий запрос:
Этот запрос требует сканирования всех 90 млн строк (согласен, быстро), так как UserId не является ключом сортировки. Ранее мы решили эту задачу, используя материализованное представление в качестве справочника для PostId. Эта же проблема может быть решена с помощью проекции. Команда ниже добавляет проекцию для ORDER BY user_id.
Обратите внимание, что сначала мы должны создать проекцию, а затем материализовать ее. Эта последняя команда заставляет данные храниться дважды на диске в двух разных порядках. Проекция также может быть определена при создании данных, как показано ниже, и будет автоматически поддерживаться по мере вставки данных.
Если проекция создается через ALTER, создание происходит асинхронно, когда команда MATERIALIZE PROJECTION выдается. Пользователи могут подтвердить ход этой операции с помощью следующего запроса, ожидая is_done=1.
Если мы повторим вышеуказанный запрос, мы увидим, что производительность значительно улучшилась за счет дополнительного хранения.
С помощью команды EXPLAIN мы также подтверждаем, что проекция была использована для обработки этого запроса:
Когда использовать проекции
Проекции являются привлекательной функцией для новых пользователей, поскольку они автоматически поддерживаются при вставке данных. Кроме того, запросы можно отправлять в одну таблицу, где проекции используются, когда это возможно, для ускорения времени ответа.
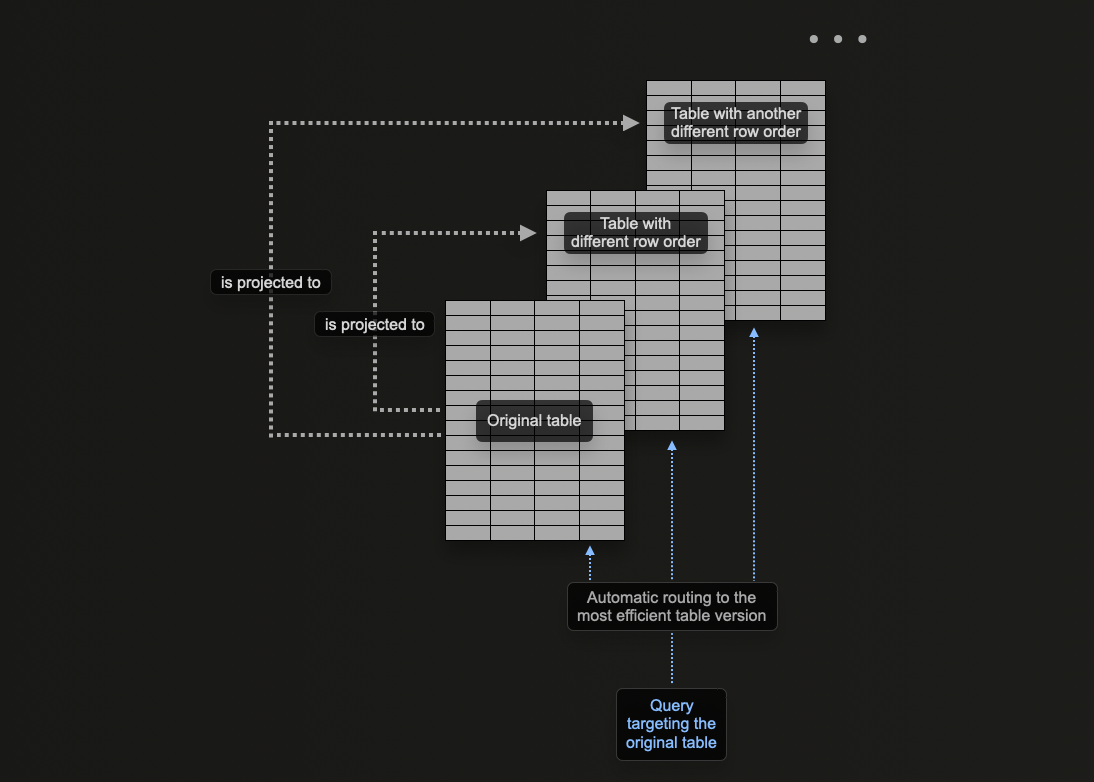
Это контрастирует с материализованными представлениями, где пользователю необходимо выбрать соответствующую оптимизированную целевую таблицу или переписать свой запрос в зависимости от фильтров. Это ставит больший акцент на пользовательских приложениях и увеличивает сложность на стороне клиента.
Несмотря на эти преимущества, проекции имеют некоторые внутренние ограничения, о которых пользователи должны быть осведомлены и, следовательно, должны использоваться избирательно.
- Проекции не позволяют использовать различные TTL для исходной таблицы и (скрытой) целевой таблицы, материализованные представления допускают разные TTL.
- Проекции в настоящее время не поддерживают
optimize_read_in_orderдля (скрытой) целевой таблицы. - Легковесные обновления и удаления не поддерживаются для таблиц с проекциями.
- Материализованные представления могут быть соединены: целевая таблица одного материализованного представления может быть исходной таблицей для другого материализованного представления и т.д. Это невозможно с проекциями.
- Проекции не поддерживают соединения; материализованные представления поддерживают.
- Проекции не поддерживают фильтры (условие WHERE); материализованные представления поддерживают.
Мы рекомендуем использовать проекции, когда:
- Необходимо полное переупорядочение данных. Хотя выражение в проекции может теоретически использовать
GROUP BY, материализованные представления более эффективны для поддержания агрегатов. Оптимизатор запросов также с большей вероятностью использует проекции, которые используют простое переупорядочение, т.е.SELECT * ORDER BY x. Пользователи могут выбрать подмножество столбцов в этом выражении, чтобы уменьшить используемое место. - Пользователи уверены в связанном увеличении занимаемого места и накладных расходов на запись данных дважды. Проверьте влияние на скорость вставки и оцените накладные расходы на хранение.